Text classification: OCR error¶
[1]:
import warnings
from abc import ABC, abstractmethod
import matplotlib.pyplot as plt
import numpy as np
from numba import NumbaDeprecationWarning, NumbaWarning
from numpy.random import RandomState
from sklearn.exceptions import ConvergenceWarning
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.svm import LinearSVC
from dpemu import runner
from dpemu.dataset_utils import load_newsgroups
from dpemu.filters.text import OCRError
from dpemu.ml_utils import reduce_dimensions_sparse
from dpemu.nodes.array import Array
from dpemu.pg_utils import load_ocr_error_params, normalize_ocr_error_params
from dpemu.plotting_utils import visualize_best_model_params, visualize_scores, visualize_classes, \
print_results_by_model, visualize_confusion_matrices
from dpemu.utils import get_project_root
warnings.simplefilter("ignore", category=ConvergenceWarning)
warnings.simplefilter("ignore", category=NumbaDeprecationWarning)
warnings.simplefilter("ignore", category=NumbaWarning)
[2]:
def get_data():
data, labels, label_names, dataset_name = load_newsgroups("all", 10)
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=.2,
random_state=RandomState(42))
return train_data, test_data, train_labels, test_labels, label_names, dataset_name
[3]:
def get_err_root_node():
err_root_node = Array()
err_root_node.addfilter(OCRError("normalized_params", "p"))
return err_root_node
[4]:
def get_err_params_list():
p_steps = np.linspace(0, .98, num=8)
params = load_ocr_error_params(f"{get_project_root()}/data/example_ocr_error_config.json")
normalized_params = normalize_ocr_error_params(params)
err_params_list = [{
"p": p,
"normalized_params": normalized_params
} for p in p_steps]
return err_params_list
[5]:
class Preprocessor:
def __init__(self):
self.random_state = RandomState(0)
def run(self, train_data, test_data, _):
vectorizer = TfidfVectorizer(max_df=0.5, min_df=2, stop_words="english")
vectorized_train_data = vectorizer.fit_transform(train_data)
vectorized_test_data = vectorizer.transform(test_data)
reduced_test_data = reduce_dimensions_sparse(vectorized_test_data, self.random_state)
return vectorized_train_data, vectorized_test_data, {"reduced_test_data": reduced_test_data}
[6]:
class AbstractModel(ABC):
def __init__(self):
self.random_state = RandomState(42)
@abstractmethod
def get_fitted_model(self, train_data, train_labels, params):
pass
def run(self, train_data, test_data, params):
train_labels = params["train_labels"]
test_labels = params["test_labels"]
fitted_model = self.get_fitted_model(train_data, train_labels, params)
predicted_test_labels = fitted_model.predict(test_data)
cm = confusion_matrix(test_labels, predicted_test_labels)
return {
"confusion_matrix": cm,
"predicted_test_labels": predicted_test_labels,
"test_mean_accuracy": round(np.mean(predicted_test_labels == test_labels), 3),
"train_mean_accuracy": fitted_model.score(train_data, train_labels),
}
class MultinomialNBModel(AbstractModel):
def __init__(self):
super().__init__()
def get_fitted_model(self, train_data, train_labels, params):
return MultinomialNB(params["alpha"]).fit(train_data, train_labels)
class LinearSVCModel(AbstractModel):
def __init__(self):
super().__init__()
def get_fitted_model(self, train_data, train_labels, params):
return LinearSVC(C=params["C"], random_state=self.random_state).fit(train_data, train_labels)
[7]:
def get_model_params_dict_list(train_labels, test_labels):
alpha_steps = [10 ** i for i in range(-4, 1)]
C_steps = [10 ** k for k in range(-3, 2)]
model_params_base = {"train_labels": train_labels, "test_labels": test_labels}
return [
{
"model": MultinomialNBModel,
"params_list": [{"alpha": alpha, **model_params_base} for alpha in alpha_steps],
"use_clean_train_data": False
},
{
"model": MultinomialNBModel,
"params_list": [{"alpha": alpha, **model_params_base} for alpha in alpha_steps],
"use_clean_train_data": True
},
{
"model": LinearSVCModel,
"params_list": [{"C": C, **model_params_base} for C in C_steps],
"use_clean_train_data": False
},
{
"model": LinearSVCModel,
"params_list": [{"C": C, **model_params_base} for C in C_steps],
"use_clean_train_data": True
},
]
[8]:
def visualize(df, dataset_name, label_names, test_data):
visualize_scores(
df,
score_names=["test_mean_accuracy", "train_mean_accuracy"],
is_higher_score_better=[True, True],
err_param_name="p",
title=f"{dataset_name} classification scores with added error"
)
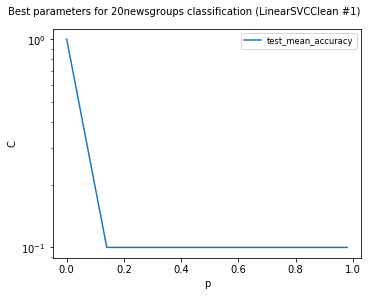
visualize_best_model_params(
df,
"MultinomialNB",
model_params=["alpha"],
score_names=["test_mean_accuracy"],
is_higher_score_better=[True],
err_param_name="p",
title=f"Best parameters for {dataset_name} classification",
y_log=True
)
visualize_best_model_params(
df,
"LinearSVC",
model_params=["C"],
score_names=["test_mean_accuracy"],
is_higher_score_better=[True],
err_param_name="p",
title=f"Best parameters for {dataset_name} classification",
y_log=True
)
visualize_classes(
df,
label_names,
err_param_name="p",
reduced_data_column="reduced_test_data",
labels_column="test_labels",
cmap="tab20",
title=f"{dataset_name} test set (n={len(test_data)}) true classes with added error"
)
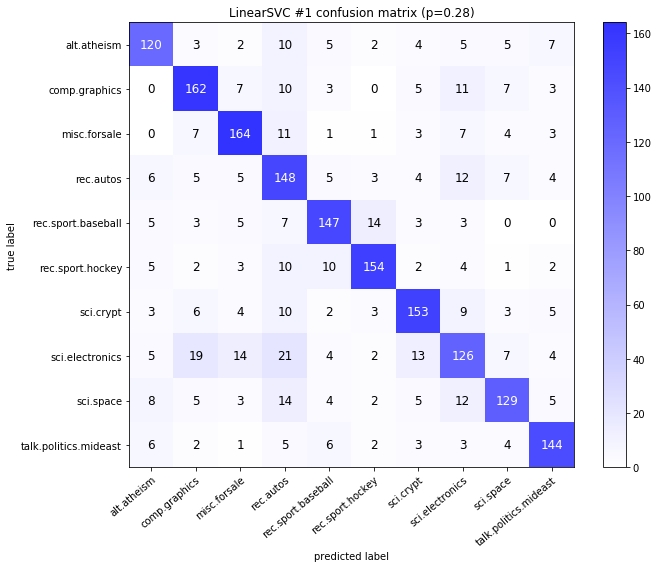
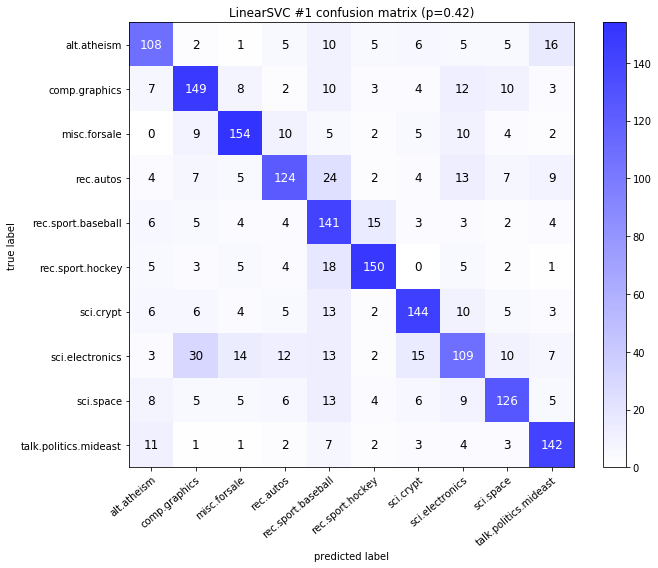
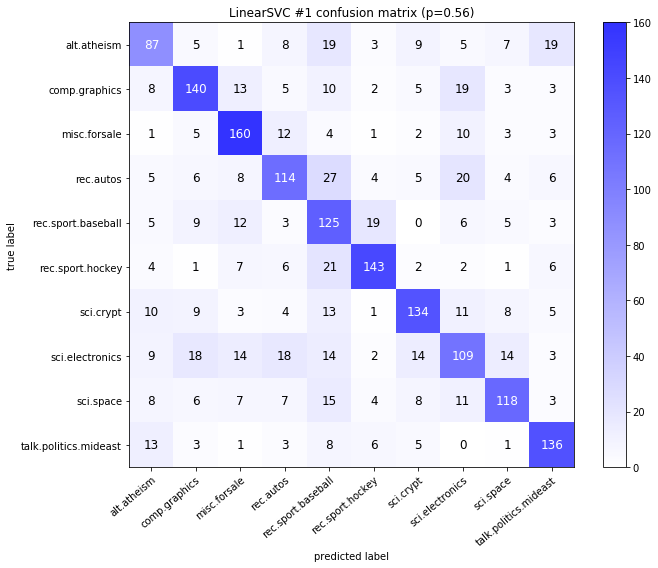
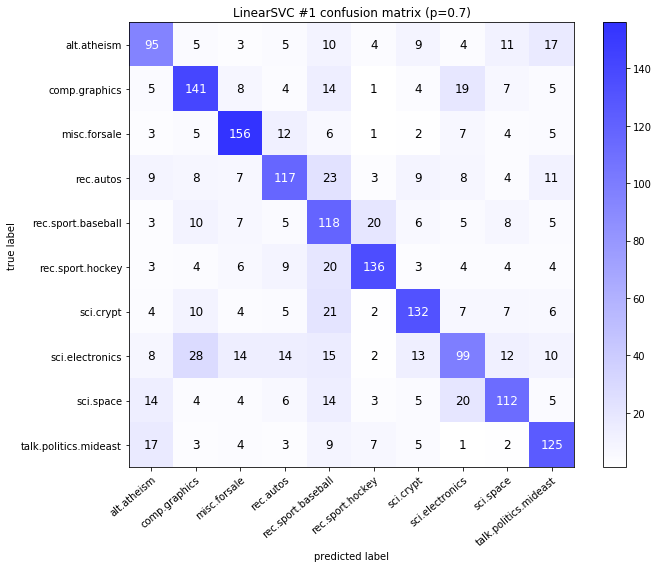
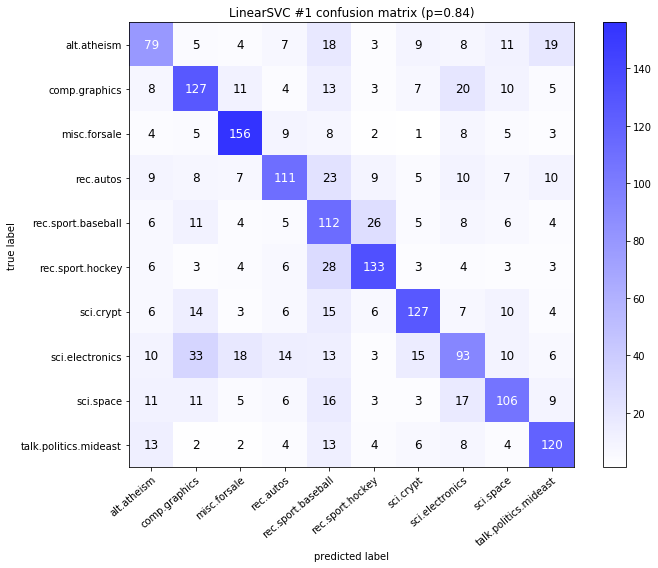
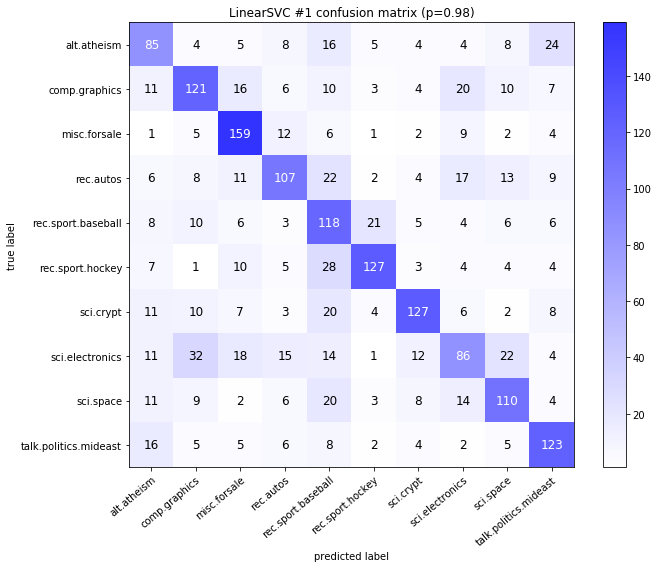
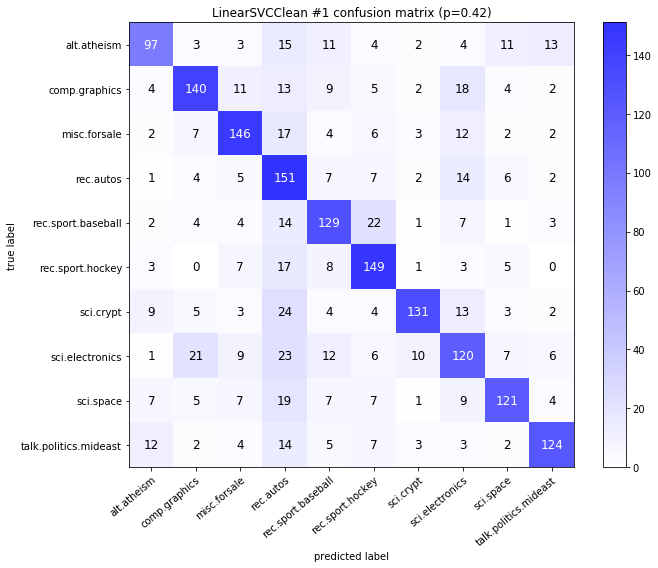
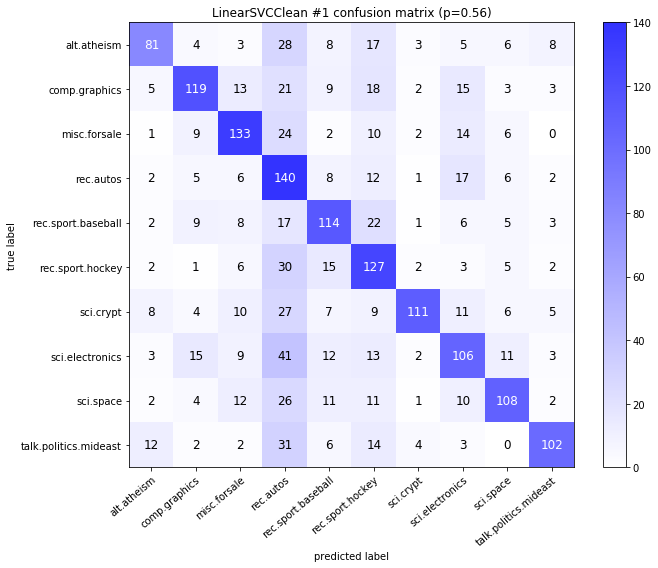
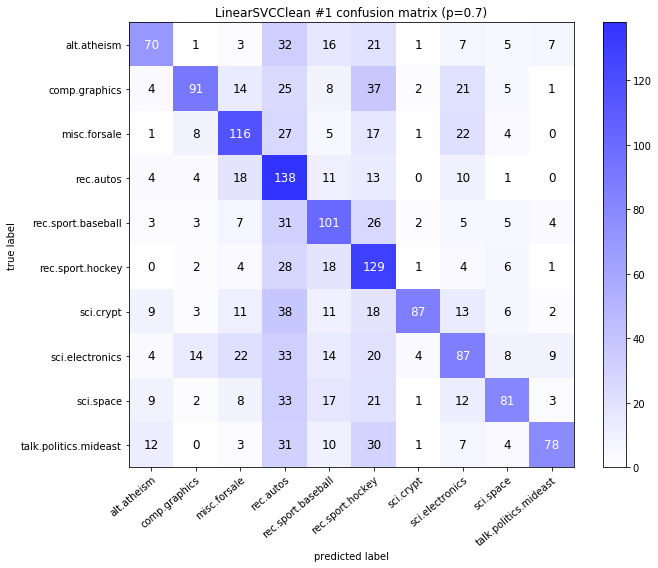
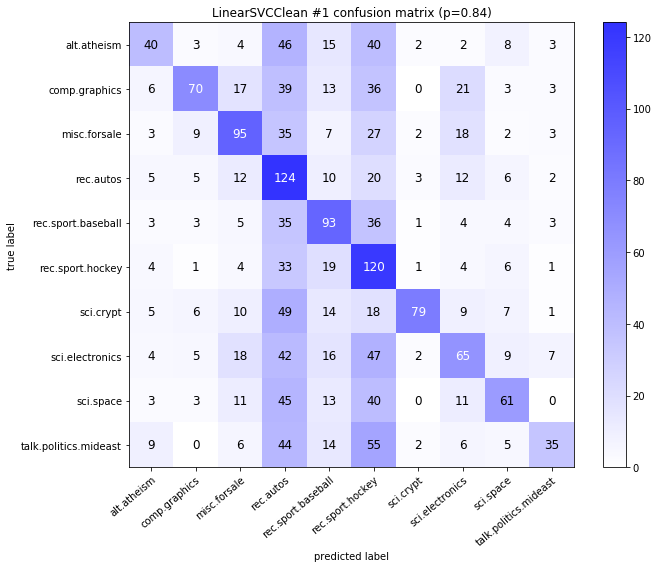
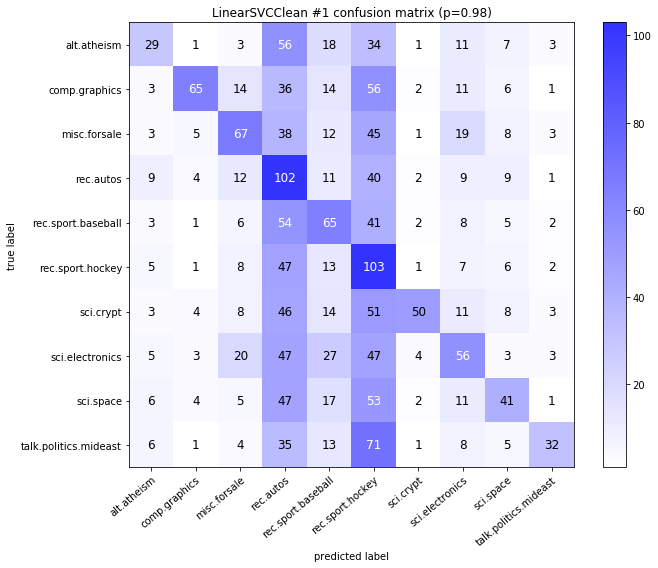
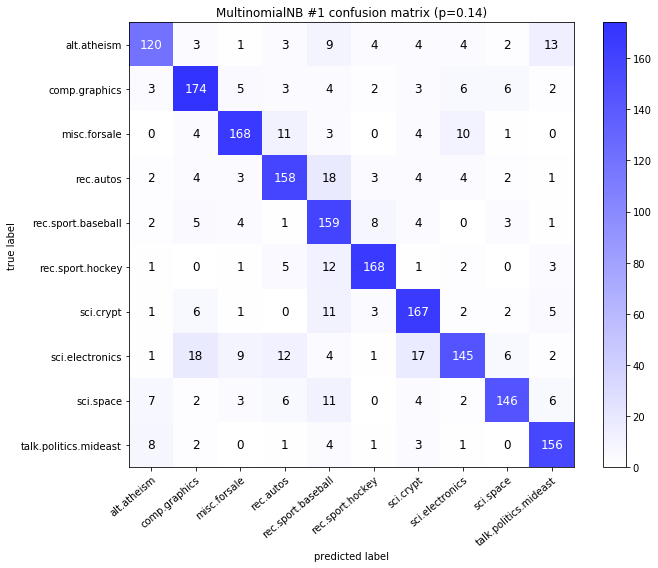
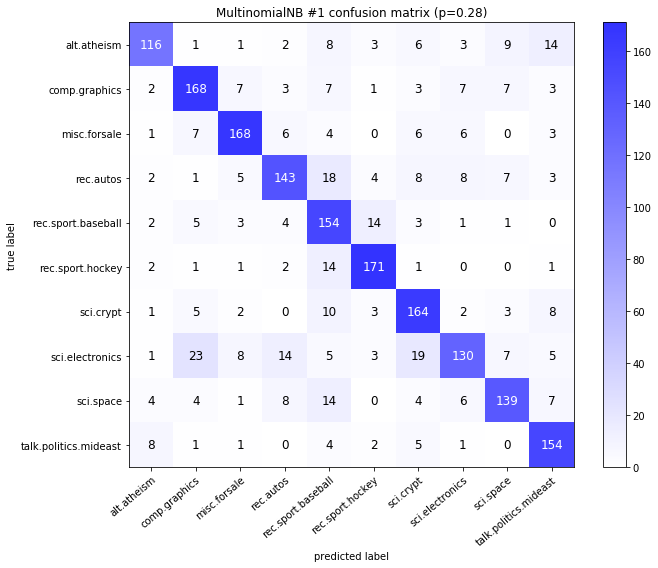
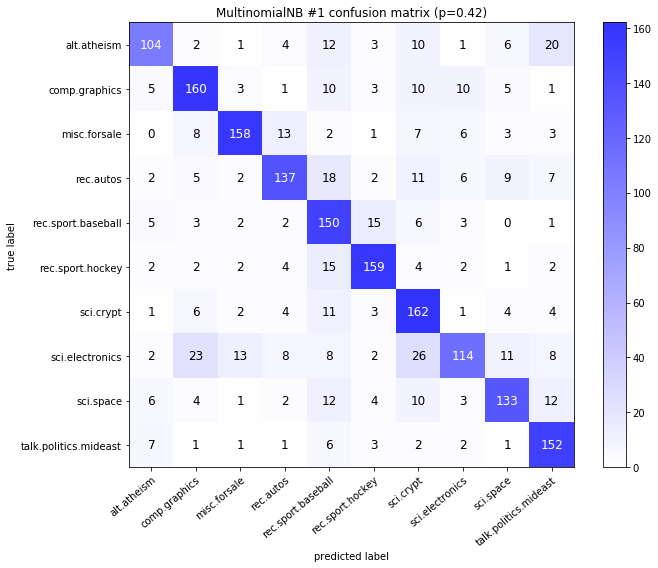
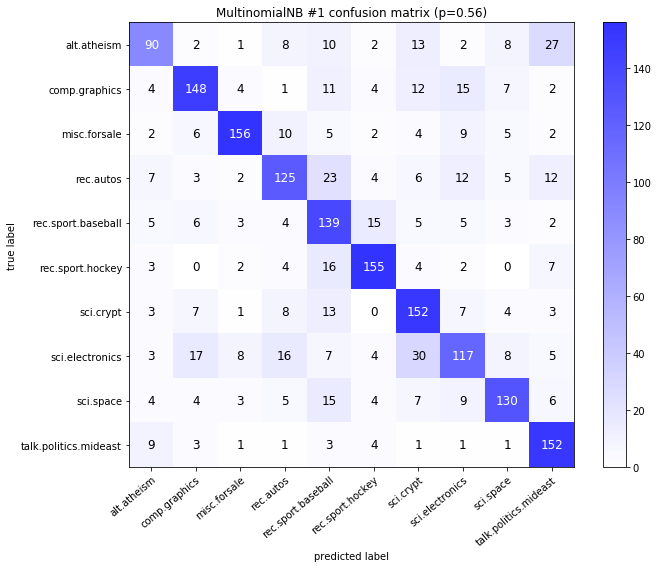
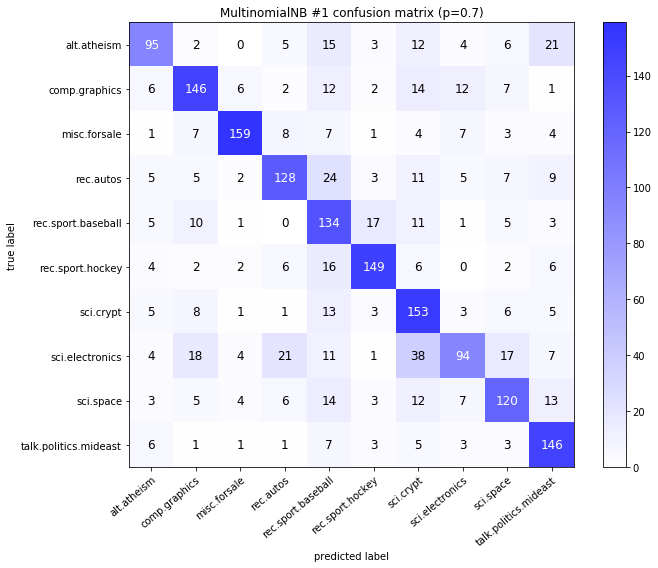
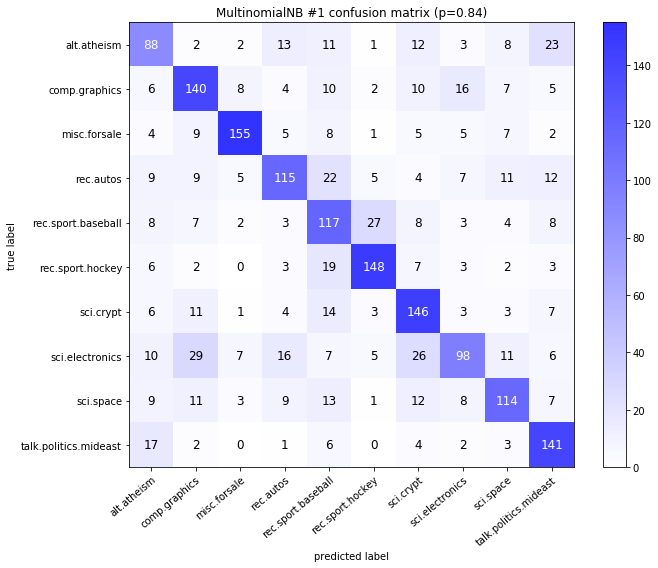
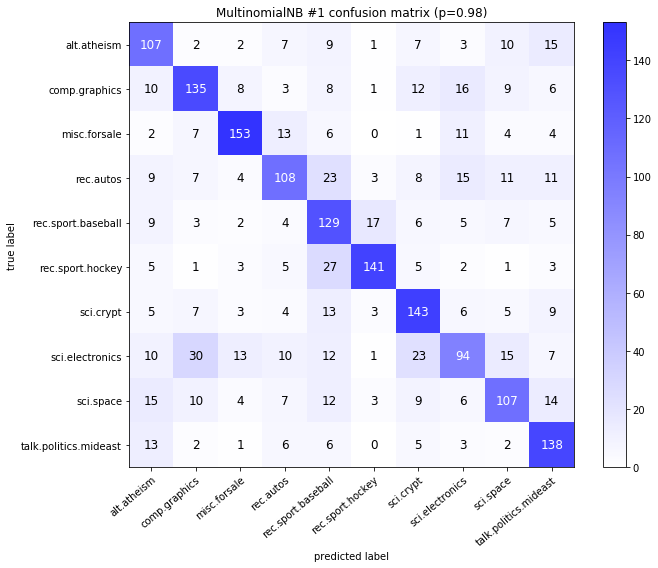
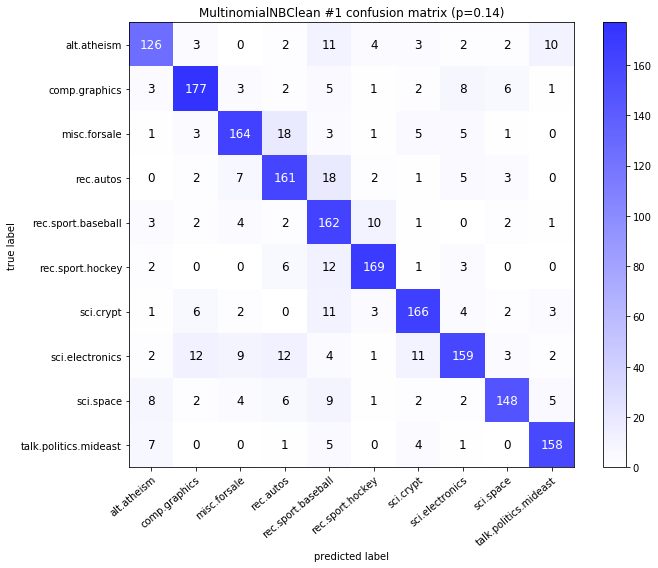
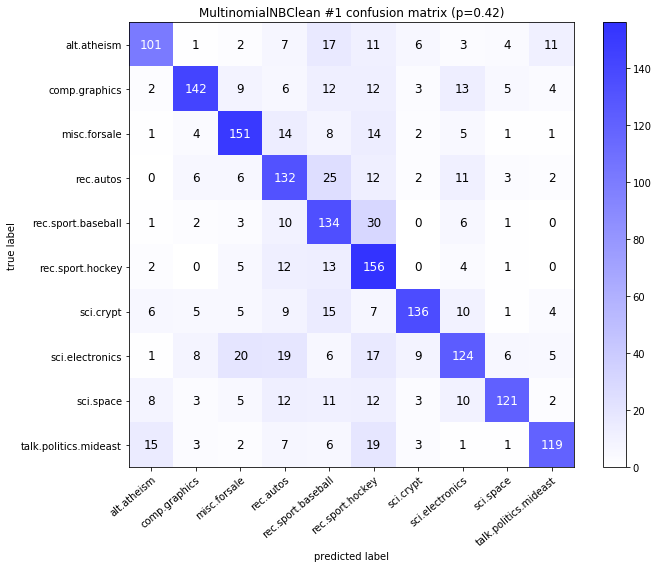
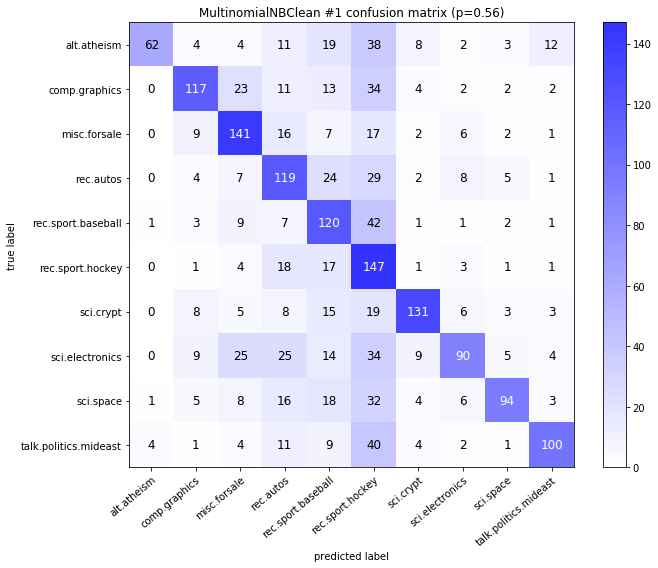
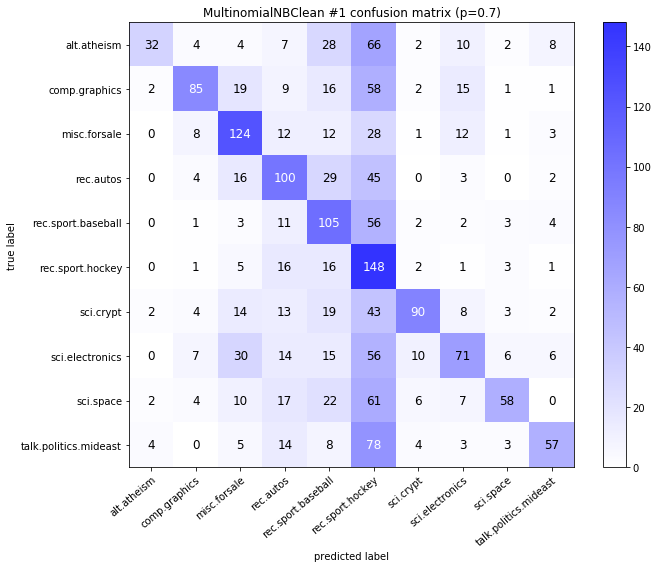
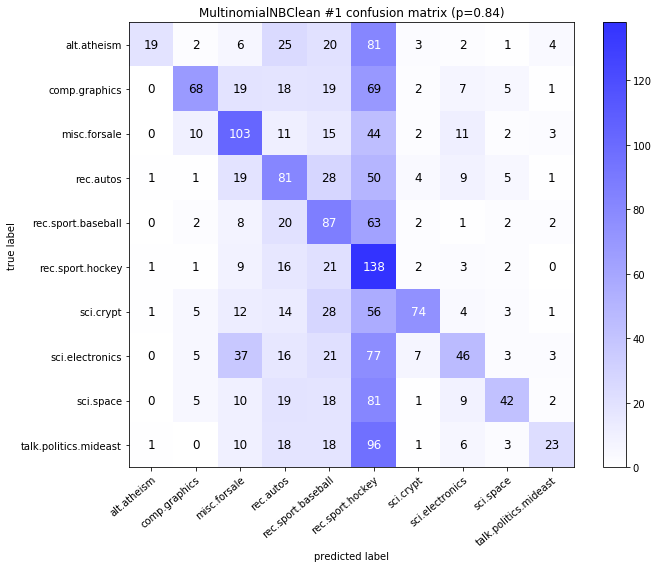
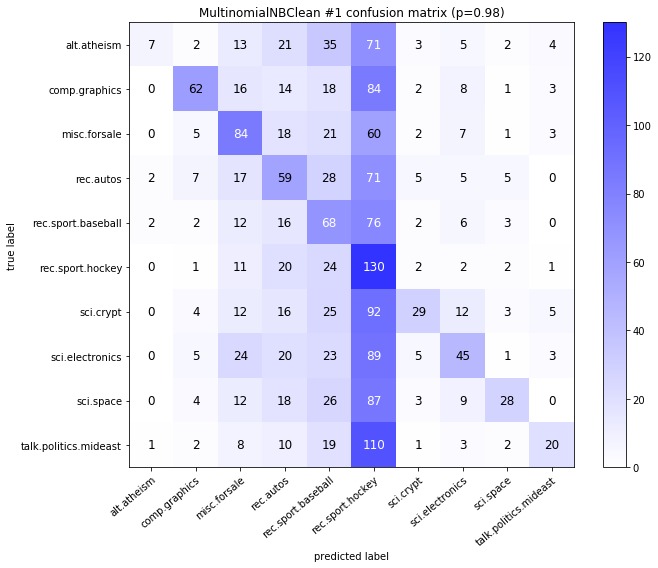
visualize_confusion_matrices(
df,
label_names,
score_name="test_mean_accuracy",
is_higher_score_better=True,
err_param_name="p",
labels_col="test_labels",
predictions_col="predicted_test_labels",
)
plt.show()
[9]:
def main():
train_data, test_data, train_labels, test_labels, label_names, dataset_name = get_data()
df = runner.run(
train_data=train_data,
test_data=test_data,
preproc=Preprocessor,
preproc_params=None,
err_root_node=get_err_root_node(),
err_params_list=get_err_params_list(),
model_params_dict_list=get_model_params_dict_list(train_labels, test_labels),
)
print_results_by_model(df, dropped_columns=[
"train_labels", "test_labels", "reduced_test_data", "confusion_matrix", "predicted_test_labels",
"normalized_params"
])
visualize(df, dataset_name, label_names, test_data)
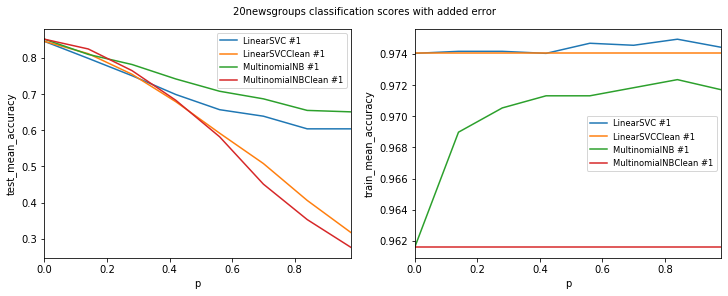
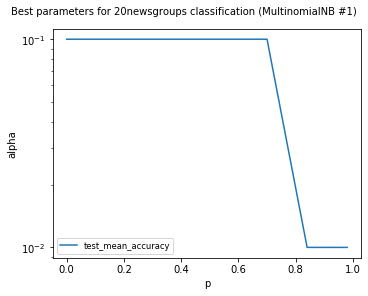
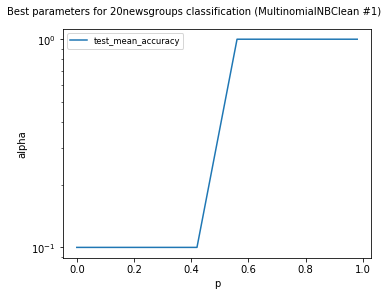
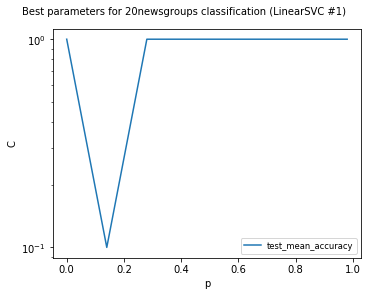
Models LinearSVCClean and MultinomialNBClean have been trained with clean data and LinearSVC and MultinomialNB with erroneus data.
[10]:
main()
100%|██████████| 8/8 [09:23<00:00, 84.65s/it]
LinearSVC #1
| test_mean_accuracy | train_mean_accuracy | p | C | time_err | time_pre | time_mod | |
|---|---|---|---|---|---|---|---|
| 0 | 0.720 | 0.792343 | 0.00 | 0.001 | 14.081 | 20.823 | 0.199 |
| 1 | 0.809 | 0.884620 | 0.00 | 0.010 | 14.081 | 20.823 | 0.251 |
| 2 | 0.842 | 0.946658 | 0.00 | 0.100 | 14.081 | 20.823 | 0.289 |
| 3 | 0.846 | 0.973005 | 0.00 | 1.000 | 14.081 | 20.823 | 0.461 |
| 4 | 0.835 | 0.974043 | 0.00 | 10.000 | 14.081 | 20.823 | 2.246 |
| 5 | 0.645 | 0.760286 | 0.14 | 0.001 | 77.115 | 21.137 | 0.266 |
| 6 | 0.751 | 0.879948 | 0.14 | 0.010 | 77.115 | 21.137 | 0.299 |
| 7 | 0.799 | 0.951979 | 0.14 | 0.100 | 77.115 | 21.137 | 0.370 |
| 8 | 0.798 | 0.973783 | 0.14 | 1.000 | 77.115 | 21.137 | 0.625 |
| 9 | 0.789 | 0.974173 | 0.14 | 10.000 | 77.115 | 21.137 | 3.082 |
| 10 | 0.591 | 0.719533 | 0.28 | 0.001 | 140.397 | 20.408 | 0.264 |
| 11 | 0.693 | 0.869825 | 0.28 | 0.010 | 140.397 | 20.408 | 0.295 |
| 12 | 0.737 | 0.956132 | 0.28 | 0.100 | 140.397 | 20.408 | 0.376 |
| 13 | 0.751 | 0.973783 | 0.28 | 1.000 | 140.397 | 20.408 | 0.662 |
| 14 | 0.742 | 0.974173 | 0.28 | 10.000 | 140.397 | 20.408 | 3.285 |
| 15 | 0.510 | 0.675146 | 0.42 | 0.001 | 220.260 | 21.367 | 0.296 |
| 16 | 0.630 | 0.848799 | 0.42 | 0.010 | 220.260 | 21.367 | 0.387 |
| 17 | 0.692 | 0.956652 | 0.42 | 0.100 | 220.260 | 21.367 | 0.425 |
| 18 | 0.699 | 0.973394 | 0.42 | 1.000 | 220.260 | 21.367 | 0.748 |
| 19 | 0.691 | 0.974043 | 0.42 | 10.000 | 220.260 | 21.367 | 3.867 |
| 20 | 0.443 | 0.627255 | 0.56 | 0.001 | 260.029 | 20.559 | 0.285 |
| 21 | 0.557 | 0.815185 | 0.56 | 0.010 | 260.029 | 20.559 | 0.342 |
| 22 | 0.642 | 0.957949 | 0.56 | 0.100 | 260.029 | 20.559 | 0.417 |
| 23 | 0.657 | 0.974043 | 0.56 | 1.000 | 260.029 | 20.559 | 0.760 |
| 24 | 0.650 | 0.974692 | 0.56 | 10.000 | 260.029 | 20.559 | 4.079 |
| 25 | 0.396 | 0.586892 | 0.70 | 0.001 | 345.086 | 20.691 | 0.283 |
| 26 | 0.504 | 0.788709 | 0.70 | 0.010 | 345.086 | 20.691 | 0.353 |
| 27 | 0.624 | 0.956003 | 0.70 | 0.100 | 345.086 | 20.691 | 0.417 |
| 28 | 0.639 | 0.974043 | 0.70 | 1.000 | 345.086 | 20.691 | 0.764 |
| 29 | 0.627 | 0.974562 | 0.70 | 10.000 | 345.086 | 20.691 | 4.118 |
| 30 | 0.371 | 0.575730 | 0.84 | 0.001 | 379.122 | 21.887 | 0.282 |
| 31 | 0.466 | 0.776639 | 0.84 | 0.010 | 379.122 | 21.887 | 0.349 |
| 32 | 0.581 | 0.958339 | 0.84 | 0.100 | 379.122 | 21.887 | 0.415 |
| 33 | 0.604 | 0.974043 | 0.84 | 1.000 | 379.122 | 21.887 | 0.762 |
| 34 | 0.603 | 0.974951 | 0.84 | 10.000 | 379.122 | 21.887 | 4.236 |
| 35 | 0.357 | 0.554705 | 0.98 | 0.001 | 532.418 | 21.617 | 0.286 |
| 36 | 0.453 | 0.757430 | 0.98 | 0.010 | 532.418 | 21.617 | 0.360 |
| 37 | 0.580 | 0.955354 | 0.98 | 0.100 | 532.418 | 21.617 | 0.419 |
| 38 | 0.604 | 0.973653 | 0.98 | 1.000 | 532.418 | 21.617 | 0.774 |
| 39 | 0.592 | 0.974432 | 0.98 | 10.000 | 532.418 | 21.617 | 4.261 |
LinearSVCClean #1
| test_mean_accuracy | train_mean_accuracy | p | C | time_err | time_pre | time_mod | |
|---|---|---|---|---|---|---|---|
| 0 | 0.720 | 0.792343 | 0.00 | 0.001 | 14.081 | 20.823 | 0.197 |
| 1 | 0.809 | 0.884620 | 0.00 | 0.010 | 14.081 | 20.823 | 0.250 |
| 2 | 0.842 | 0.946658 | 0.00 | 0.100 | 14.081 | 20.823 | 0.288 |
| 3 | 0.846 | 0.973005 | 0.00 | 1.000 | 14.081 | 20.823 | 0.461 |
| 4 | 0.835 | 0.974043 | 0.00 | 10.000 | 14.081 | 20.823 | 2.240 |
| 5 | 0.678 | 0.792343 | 0.14 | 0.001 | 77.115 | 21.137 | 0.206 |
| 6 | 0.771 | 0.884620 | 0.14 | 0.010 | 77.115 | 21.137 | 0.259 |
| 7 | 0.812 | 0.946658 | 0.14 | 0.100 | 77.115 | 21.137 | 0.300 |
| 8 | 0.801 | 0.973005 | 0.14 | 1.000 | 77.115 | 21.137 | 0.482 |
| 9 | 0.778 | 0.974043 | 0.14 | 10.000 | 77.115 | 21.137 | 2.384 |
| 10 | 0.627 | 0.792343 | 0.28 | 0.001 | 140.397 | 20.408 | 0.184 |
| 11 | 0.722 | 0.884620 | 0.28 | 0.010 | 140.397 | 20.408 | 0.234 |
| 12 | 0.755 | 0.946658 | 0.28 | 0.100 | 140.397 | 20.408 | 0.268 |
| 13 | 0.733 | 0.973005 | 0.28 | 1.000 | 140.397 | 20.408 | 0.428 |
| 14 | 0.718 | 0.974043 | 0.28 | 10.000 | 140.397 | 20.408 | 2.086 |
| 15 | 0.558 | 0.792343 | 0.42 | 0.001 | 220.260 | 21.367 | 0.211 |
| 16 | 0.650 | 0.884620 | 0.42 | 0.010 | 220.260 | 21.367 | 0.246 |
| 17 | 0.679 | 0.946658 | 0.42 | 0.100 | 220.260 | 21.367 | 0.281 |
| 18 | 0.661 | 0.973005 | 0.42 | 1.000 | 220.260 | 21.367 | 0.450 |
| 19 | 0.636 | 0.974043 | 0.42 | 10.000 | 220.260 | 21.367 | 2.200 |
| 20 | 0.457 | 0.792343 | 0.56 | 0.001 | 260.029 | 20.559 | 0.183 |
| 21 | 0.564 | 0.884620 | 0.56 | 0.010 | 260.029 | 20.559 | 0.233 |
| 22 | 0.592 | 0.946658 | 0.56 | 0.100 | 260.029 | 20.559 | 0.270 |
| 23 | 0.551 | 0.973005 | 0.56 | 1.000 | 260.029 | 20.559 | 0.433 |
| 24 | 0.523 | 0.974043 | 0.56 | 10.000 | 260.029 | 20.559 | 2.115 |
| 25 | 0.366 | 0.792343 | 0.70 | 0.001 | 345.086 | 20.691 | 0.177 |
| 26 | 0.474 | 0.884620 | 0.70 | 0.010 | 345.086 | 20.691 | 0.224 |
| 27 | 0.508 | 0.946658 | 0.70 | 0.100 | 345.086 | 20.691 | 0.258 |
| 28 | 0.461 | 0.973005 | 0.70 | 1.000 | 345.086 | 20.691 | 0.418 |
| 29 | 0.418 | 0.974043 | 0.70 | 10.000 | 345.086 | 20.691 | 2.038 |
| 30 | 0.299 | 0.792343 | 0.84 | 0.001 | 379.122 | 21.887 | 0.178 |
| 31 | 0.382 | 0.884620 | 0.84 | 0.010 | 379.122 | 21.887 | 0.226 |
| 32 | 0.406 | 0.946658 | 0.84 | 0.100 | 379.122 | 21.887 | 0.260 |
| 33 | 0.371 | 0.973005 | 0.84 | 1.000 | 379.122 | 21.887 | 0.417 |
| 34 | 0.343 | 0.974043 | 0.84 | 10.000 | 379.122 | 21.887 | 2.042 |
| 35 | 0.239 | 0.792343 | 0.98 | 0.001 | 532.418 | 21.617 | 0.177 |
| 36 | 0.311 | 0.884620 | 0.98 | 0.010 | 532.418 | 21.617 | 0.224 |
| 37 | 0.317 | 0.946658 | 0.98 | 0.100 | 532.418 | 21.617 | 0.259 |
| 38 | 0.281 | 0.973005 | 0.98 | 1.000 | 532.418 | 21.617 | 0.415 |
| 39 | 0.257 | 0.974043 | 0.98 | 10.000 | 532.418 | 21.617 | 2.037 |
MultinomialNB #1
| test_mean_accuracy | train_mean_accuracy | p | alpha | time_err | time_pre | time_mod | |
|---|---|---|---|---|---|---|---|
| 0 | 0.834 | 0.961583 | 0.00 | 0.0001 | 14.081 | 20.823 | 0.038 |
| 1 | 0.843 | 0.960675 | 0.00 | 0.0010 | 14.081 | 20.823 | 0.032 |
| 2 | 0.851 | 0.958209 | 0.00 | 0.0100 | 14.081 | 20.823 | 0.032 |
| 3 | 0.852 | 0.951979 | 0.00 | 0.1000 | 14.081 | 20.823 | 0.032 |
| 4 | 0.832 | 0.925892 | 0.00 | 1.0000 | 14.081 | 20.823 | 0.032 |
| 5 | 0.763 | 0.968981 | 0.14 | 0.0001 | 77.115 | 21.137 | 0.054 |
| 6 | 0.786 | 0.968981 | 0.14 | 0.0010 | 77.115 | 21.137 | 0.044 |
| 7 | 0.805 | 0.968332 | 0.14 | 0.0100 | 77.115 | 21.137 | 0.044 |
| 8 | 0.810 | 0.966126 | 0.14 | 0.1000 | 77.115 | 21.137 | 0.044 |
| 9 | 0.794 | 0.940818 | 0.14 | 1.0000 | 77.115 | 21.137 | 0.057 |
| 10 | 0.728 | 0.970539 | 0.28 | 0.0001 | 140.397 | 20.408 | 0.048 |
| 11 | 0.747 | 0.970409 | 0.28 | 0.0010 | 140.397 | 20.408 | 0.046 |
| 12 | 0.770 | 0.970019 | 0.28 | 0.0100 | 140.397 | 20.408 | 0.046 |
| 13 | 0.782 | 0.968073 | 0.28 | 0.1000 | 140.397 | 20.408 | 0.046 |
| 14 | 0.736 | 0.946009 | 0.28 | 1.0000 | 140.397 | 20.408 | 0.046 |
| 15 | 0.691 | 0.971317 | 0.42 | 0.0001 | 220.260 | 21.367 | 0.073 |
| 16 | 0.706 | 0.971317 | 0.42 | 0.0010 | 220.260 | 21.367 | 0.055 |
| 17 | 0.736 | 0.971317 | 0.42 | 0.0100 | 220.260 | 21.367 | 0.055 |
| 18 | 0.742 | 0.970409 | 0.42 | 0.1000 | 220.260 | 21.367 | 0.055 |
| 19 | 0.665 | 0.946398 | 0.42 | 1.0000 | 220.260 | 21.367 | 0.055 |
| 20 | 0.665 | 0.971317 | 0.56 | 0.0001 | 260.029 | 20.559 | 0.053 |
| 21 | 0.691 | 0.971317 | 0.56 | 0.0010 | 260.029 | 20.559 | 0.050 |
| 22 | 0.705 | 0.970928 | 0.56 | 0.0100 | 260.029 | 20.559 | 0.050 |
| 23 | 0.708 | 0.970279 | 0.56 | 0.1000 | 260.029 | 20.559 | 0.050 |
| 24 | 0.601 | 0.941077 | 0.56 | 1.0000 | 260.029 | 20.559 | 0.050 |
| 25 | 0.625 | 0.971836 | 0.70 | 0.0001 | 345.086 | 20.691 | 0.056 |
| 26 | 0.649 | 0.971836 | 0.70 | 0.0010 | 345.086 | 20.691 | 0.050 |
| 27 | 0.678 | 0.971836 | 0.70 | 0.0100 | 345.086 | 20.691 | 0.050 |
| 28 | 0.687 | 0.971058 | 0.70 | 0.1000 | 345.086 | 20.691 | 0.050 |
| 29 | 0.551 | 0.928358 | 0.70 | 1.0000 | 345.086 | 20.691 | 0.050 |
| 30 | 0.615 | 0.972356 | 0.84 | 0.0001 | 379.122 | 21.887 | 0.053 |
| 31 | 0.637 | 0.972356 | 0.84 | 0.0010 | 379.122 | 21.887 | 0.050 |
| 32 | 0.655 | 0.972226 | 0.84 | 0.0100 | 379.122 | 21.887 | 0.050 |
| 33 | 0.649 | 0.972226 | 0.84 | 0.1000 | 379.122 | 21.887 | 0.050 |
| 34 | 0.508 | 0.923945 | 0.84 | 1.0000 | 379.122 | 21.887 | 0.050 |
| 35 | 0.595 | 0.971707 | 0.98 | 0.0001 | 532.418 | 21.617 | 0.055 |
| 36 | 0.618 | 0.971707 | 0.98 | 0.0010 | 532.418 | 21.617 | 0.051 |
| 37 | 0.651 | 0.971707 | 0.98 | 0.0100 | 532.418 | 21.617 | 0.051 |
| 38 | 0.650 | 0.970668 | 0.98 | 0.1000 | 532.418 | 21.617 | 0.051 |
| 39 | 0.480 | 0.912914 | 0.98 | 1.0000 | 532.418 | 21.617 | 0.051 |
MultinomialNBClean #1
| test_mean_accuracy | train_mean_accuracy | p | alpha | time_err | time_pre | time_mod | |
|---|---|---|---|---|---|---|---|
| 0 | 0.834 | 0.961583 | 0.00 | 0.0001 | 14.081 | 20.823 | 0.035 |
| 1 | 0.843 | 0.960675 | 0.00 | 0.0010 | 14.081 | 20.823 | 0.032 |
| 2 | 0.851 | 0.958209 | 0.00 | 0.0100 | 14.081 | 20.823 | 0.032 |
| 3 | 0.852 | 0.951979 | 0.00 | 0.1000 | 14.081 | 20.823 | 0.032 |
| 4 | 0.832 | 0.925892 | 0.00 | 1.0000 | 14.081 | 20.823 | 0.032 |
| 5 | 0.778 | 0.961583 | 0.14 | 0.0001 | 77.115 | 21.137 | 0.044 |
| 6 | 0.801 | 0.960675 | 0.14 | 0.0010 | 77.115 | 21.137 | 0.031 |
| 7 | 0.818 | 0.958209 | 0.14 | 0.0100 | 77.115 | 21.137 | 0.031 |
| 8 | 0.825 | 0.951979 | 0.14 | 0.1000 | 77.115 | 21.137 | 0.031 |
| 9 | 0.808 | 0.925892 | 0.14 | 1.0000 | 77.115 | 21.137 | 0.031 |
| 10 | 0.708 | 0.961583 | 0.28 | 0.0001 | 140.397 | 20.408 | 0.033 |
| 11 | 0.729 | 0.960675 | 0.28 | 0.0010 | 140.397 | 20.408 | 0.029 |
| 12 | 0.751 | 0.958209 | 0.28 | 0.0100 | 140.397 | 20.408 | 0.029 |
| 13 | 0.765 | 0.951979 | 0.28 | 0.1000 | 140.397 | 20.408 | 0.029 |
| 14 | 0.754 | 0.925892 | 0.28 | 1.0000 | 140.397 | 20.408 | 0.029 |
| 15 | 0.575 | 0.961583 | 0.42 | 0.0001 | 220.260 | 21.367 | 0.034 |
| 16 | 0.605 | 0.960675 | 0.42 | 0.0010 | 220.260 | 21.367 | 0.029 |
| 17 | 0.643 | 0.958209 | 0.42 | 0.0100 | 220.260 | 21.367 | 0.033 |
| 18 | 0.683 | 0.951979 | 0.42 | 0.1000 | 220.260 | 21.367 | 0.029 |
| 19 | 0.680 | 0.925892 | 0.42 | 1.0000 | 220.260 | 21.367 | 0.029 |
| 20 | 0.451 | 0.961583 | 0.56 | 0.0001 | 260.029 | 20.559 | 0.031 |
| 21 | 0.477 | 0.960675 | 0.56 | 0.0010 | 260.029 | 20.559 | 0.027 |
| 22 | 0.517 | 0.958209 | 0.56 | 0.0100 | 260.029 | 20.559 | 0.027 |
| 23 | 0.563 | 0.951979 | 0.56 | 0.1000 | 260.029 | 20.559 | 0.027 |
| 24 | 0.582 | 0.925892 | 0.56 | 1.0000 | 260.029 | 20.559 | 0.027 |
| 25 | 0.337 | 0.961583 | 0.70 | 0.0001 | 345.086 | 20.691 | 0.030 |
| 26 | 0.363 | 0.960675 | 0.70 | 0.0010 | 345.086 | 20.691 | 0.026 |
| 27 | 0.387 | 0.958209 | 0.70 | 0.0100 | 345.086 | 20.691 | 0.026 |
| 28 | 0.445 | 0.951979 | 0.70 | 0.1000 | 345.086 | 20.691 | 0.026 |
| 29 | 0.451 | 0.925892 | 0.70 | 1.0000 | 345.086 | 20.691 | 0.026 |
| 30 | 0.261 | 0.961583 | 0.84 | 0.0001 | 379.122 | 21.887 | 0.031 |
| 31 | 0.272 | 0.960675 | 0.84 | 0.0010 | 379.122 | 21.887 | 0.027 |
| 32 | 0.290 | 0.958209 | 0.84 | 0.0100 | 379.122 | 21.887 | 0.027 |
| 33 | 0.320 | 0.951979 | 0.84 | 0.1000 | 379.122 | 21.887 | 0.027 |
| 34 | 0.353 | 0.925892 | 0.84 | 1.0000 | 379.122 | 21.887 | 0.027 |
| 35 | 0.216 | 0.961583 | 0.98 | 0.0001 | 532.418 | 21.617 | 0.030 |
| 36 | 0.218 | 0.960675 | 0.98 | 0.0010 | 532.418 | 21.617 | 0.027 |
| 37 | 0.233 | 0.958209 | 0.98 | 0.0100 | 532.418 | 21.617 | 0.026 |
| 38 | 0.261 | 0.951979 | 0.98 | 0.1000 | 532.418 | 21.617 | 0.026 |
| 39 | 0.276 | 0.925892 | 0.98 | 1.0000 | 532.418 | 21.617 | 0.026 |
/wrk/users/thalvari/dpEmu/dpemu/plotting_utils.py:299: RuntimeWarning: More than 20 figures have been opened. Figures created through the pyplot interface (`matplotlib.pyplot.figure`) are retained until explicitly closed and may consume too much memory. (To control this warning, see the rcParam `figure.max_open_warning`).
fig, ax = plt.subplots(figsize=(10, 8))









The notebook for this case study can be found here.